README
node关键词
事件驱动、非阻塞I/O、异步非阻塞模型、高效、轻量、高并发
node 是怎么实现的
 我们可以看到,Node.js 的结构大致分为三个层次:
我们可以看到,Node.js 的结构大致分为三个层次:
1、 Node.js 标准库,这部分是由 Javascript 编写的,即我们使用过程中直接能调用的 API。在源码中的 lib 目录下可以看到。 2、 Node bindings,这一层是 Javascript 与底层 C/C++ 能够沟通的关键,前者通过 bindings 调用后者,相互交换数据。 3、这一层是支撑 Node.js 运行的关键,由 C/C++ 实现。
- V8:Google 推出的 Javascript VM,也是 Node.js 为什么使用的是 Javascript 的关键,它为 Javascript 提供了在非浏览器端运行的环境,它的高效是 Node.js 之所以高效的原因之一。
- Libuv:它为 Node.js 提供了跨平台,线程池,事件池,异步 I/O 等能力,是 Node.js 如此强大的关键。
- C-ares:提供了异步处理 DNS 相关的能力。
- http_parser、OpenSSL、zlib 等:提供包括 http 解析、SSL、数据压缩等其他的能力。
node 执行机制
1.V8 引擎解析 JavaScript 脚本。
2.执行解析后的代码,调用 Node API(执行完同步代码后就会进入事件循环)
3.libuv 库负责 Node API 的执行。它将不同的任务分配给不同的线程,形成一个 EventLoop(事件循环),以异步的方式将任务的执行结果返回给 V8 引擎。
4.V8 引擎再将结果返回给用户。
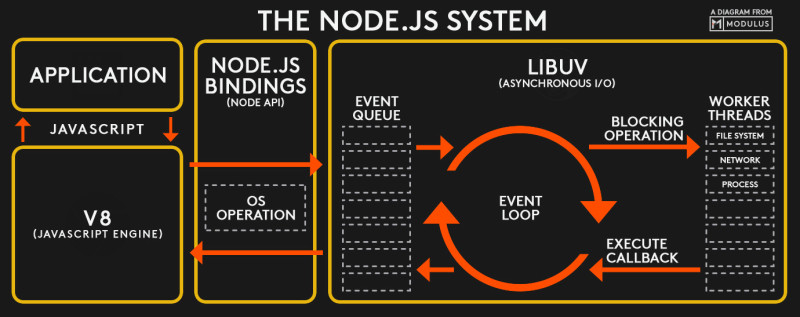
- 首先我们能看到我们的 js 代码
(APPLICATION)会先进入 v8 引擎,v8 引擎中主要是一些setTimeout之类的方法。 - 其次如果我们的代码中执行了 nodeApi,比如
require('fs').read(),node 就会交给libuv库处理,这个libuv库是别人写的,他就是 node 的事件环。 libuv库是通过单线程异步的方式来处理事件,我们可以看到work threads是个多线程的队列,通过外面event loop阻塞的方式来进行异步调用。- 等到
work threads队列中有执行完成的事件,就会通过EXECUTE CALLBACK回调给EVENT QUEUE队列,把它放入队列中。 - 最后通过事件驱动的方式,取出
EVENT QUEUE队列的事件,交给我们的应用
libuv
Node中的Event Loop是基于libuv实现的,而libuv是 Node 的新跨平台抽象层,libuv 使用异步,事件驱动的编程方式,核心是提供i/o的事件循环和异步回调。libuv 的API包含有时间,非阻塞的网络,异步文件操作,子进程等等。 Event Loop就是在libuv中实现的
ibuv 不仅仅只提供了对于不同 I/O 轮询机制的简单抽象:“句柄(handles)”和“流(streams)”也提供了对于 socket 和其他相关实例的高度抽象。同时 libuv 还提供了跨平台文件 I/O 接口和多线程接口等等。
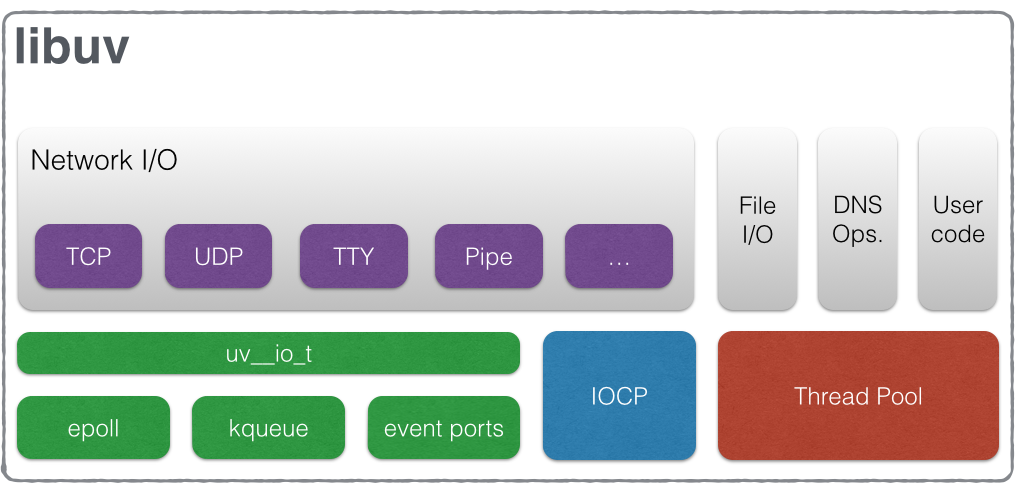
句柄(handles)和请求(requests)
为了能使用户介入事件循环(event loop),libuv 为用户提供了两个抽象:句柄和请求。
句柄表示一个在其被激活时可以执行某些操作且持久存在的对象。例如:当一个预备句柄(prepare handle)处于激活时,它的回调函数会在每次事件循环中被调用;每当一个新 TCP 连接来到时,一个 TCP 服务器句柄的连接回调函数就会被调用。
请求(通常)表示一个短暂存在的操作。这些操作可以操作于句柄,例如写请求(write requests)用于向一个句柄写入数据。但是又如 getaddrinfo 请求则不依赖于一个句柄,它们直接在事件循环上执行。
libuv 官方文档对事件循环的说明的翻译
事件循环是 libuv 的核心部分。它为所有的 I/O 操作建立了上下文,并且执行于一个单线程中。你可以在多个不同的线程中运行多个事件循环。 event loop 首先会在内部维持多个事件队列(或者叫做观察者 watcher),比如 时间队列、网络队列等等,使用者可以在 watcher 中注册回调,当事件发生时事件转入 pending 状态,再下一次循环的时候按顺序取出来执行,而 libuv 会执行一个相当于 while true 的无限循环,不断的检查各个 watcher 上面是否有需要处理的 pending 状态事件,如果有则按顺序去触发队列里面保存的事件,同时由于 libuv 的事件循环每次只会执行一个回调(不会同时执行两个回调导致并行),从而避免了竞争的发生

事件循环中的“现在时间(now)”被更新。事件循环会在一次循环迭代开始的时候缓存下当时的时间,用于减少与时间相关的系统调用次数。
如果事件循环仍是存活(alive)的,那么迭代就会开始,否则循环会立刻退出。如果一个循环内包含激活的可引用句柄,激活的请求或正在关闭的句柄,那么则认为该循环是存活的。
执行超时定时器(due timers)。所有在循环的“现在时间”之前超时的定时器都将在这个时候得到执行。
执行等待中回调(pending callbacks)。正常情况下,所有的 I/O 回调都会在轮询 I/O 后立刻被调用。但是有些情况下,回调可能会被推迟至下一次循环迭代中再执行。任何上一次循环中被推迟的回调,都将在这个时候得到执行。
执行闲置句柄回调(idle handle callbacks)。尽管它有个不怎么好听的名字,但只要这些闲置句柄是激活的,那么在每次循环迭代中它们都会执行。
执行预备回调(prepare handle)。预备回调会在循环为 I/O 阻塞前被调用。
开始计算轮询超时(poll timeout)。在为 I/O 阻塞前,事件循环会计算它即将会阻塞多长时间。以下为计算该超时的规则:
如果循环带着
UV_RUN_NOWAIT标识执行,那么超时将会是 0 。如果循环即将停止(
uv_stop()已在之前被调用),那么超时将会是 0 。如果循环内没有激活的句柄和请求,那么超时将会是 0 。
如果循环内有激活的闲置句柄,那么超时将会是 0 。
如果有正在等待被关闭的句柄,那么超时将会是 0 。
如果不符合以上所有,那么该超时将会是循环内所有定时器中最早的一个超时时间,如果没有任何一个激活的定时器,那么超时将会是无限长(infinity)。
事件循环为 I/O 阻塞。此时事件循环将会为 I/O 阻塞,持续时间为上一步中计算所得的超时时间。所有与 I/O 相关的句柄都将会监视一个指定的文件描述符,等待一个其上的读或写操作来激活它们的回调。
执行检查句柄回调(check handle callbacks)。在事件循环为 I/O 阻塞结束后,检查句柄的回调将会立刻执行。检查句柄本质上是预备句柄的对应物(counterpart)。
尽管在为 I/O 阻塞后可能并没有 I/O 回调被触发,但是仍有可能这时已经有一些定时器已经超时。若事件循环是以
UV_RUN_ONCE标识执行,那么在这时这些超时的定时器的回调将会在此时得到执行。迭代结束。如果循环以
UV_RUN_NOWAIT或UV_RUN_ONCE标识执行,迭代便会结束,并且uv_run()将会返回。如果循环以UV_RUN_DEFAULT标识执行,那么如果若它还是存活的,它就会开始下一次迭代,否则结束。
总结下 nodejs 里的异步事件
非 I/O 操作:
- 定时器(setTimeout,setInterval)
- microtask(promise)
- process.nextTick
- setImmediate
- DNS.lookup
I/O 操作:
- 网络 I/O
对于网络 I/O,各个平台的实现机制不一样,linux 是 epoll 模型,类 unix 是 kquene 、windows 下是高效的 IOCP 完成端口、SunOs 是 event ports,libuv 对这几种网络 I/O 模型进行了封装。
- 文件 I/O 与 DNS 操作
libuv 内部还维护着一个默认 4 个线程的线程池,这些线程负责执行文件 I/O 操作、DNS 操作、用户异步代码。当 js 层传递给 libuv 一个操作任务时,libuv 会把这个任务加到队列中。之后分两种情况:
1、线程池中的线程都被占用的时候,队列中任务就要进行排队等待空闲线程。
2、线程池中有可用线程时,从队列中取出这个任务执行,执行完毕后,线程归还到线程池,等待下个任务。同时以事件的方式通知 event-loop,event-loop 接收到事件执行该事件注册的回调函数。
总结下 Node 的微任务与宏任务
macro(宏任务)队列和 micro(微任务)队列
其中macrotask类型包括:
script整体代码setTimeoutsetIntervalsetImmediateI/O
microtask类型包括:
process.nextTickPromise.then(这里指浏览器实现的原生promise)
微任务和宏任务在 Node 的执行顺序
Node 10 以前:
- 执行完一个阶段的所有宏任务
- 执行完 nextTick 队列里面的内容
- 然后执行完微任务队列的内容
Node 11 以后: 和浏览器的行为统一了,都是每执行一个宏任务(setTimeout,setInterval 和 setImmediate)就执行完微任务队列。
setTimeout 和 setImmediate
二者非常相似,区别主要在于调用时机不同。
- setImmediate 设计在 poll 阶段完成时执行,即 check 阶段;
- setTimeout 设计在 poll 阶段为空闲时,且设定时间到达后执行,但它在 timer 阶段执行
网上有有一种说法,因为 setTimeout 虽然在 node 事件循环中的第一个阶段,但 setTimeout 即使将delay设置为 0 也会有 1ms+(node 做不到那么精确),那么当第一次事件循环时,setTimeout 可能还没有准备好,就将会让 setImmediate 先执行。
所以下面的代码可能会出现两种情况
setTimeout(function timeout () {
console.log('timeout');
},0);
setImmediate(function immediate () {
console.log('immediate');
});
Node eventLoop(调用 libuv 实现)
每个阶段都有一个 FIFO 队列来执行回调。虽然每个阶段都是特殊的,但通常情况下,当事件循环进入给定的阶段时,它将执行特定于该阶段的任何操作,然后在该阶段的队列中执行回调,直到队列用尽或最大回调数已执行。当该队列已用尽或达到回调限制,事件循环将移动到下一阶段,等等。 由于这些操作中的任何一个都可能计划 更多的 操作,并且在 轮询 阶段处理的新事件由内核排队,因此在处理轮询事件时,轮询事件可以排队。因此,长时间运行回调可以允许轮询阶段运行大量长于计时器的阈值。
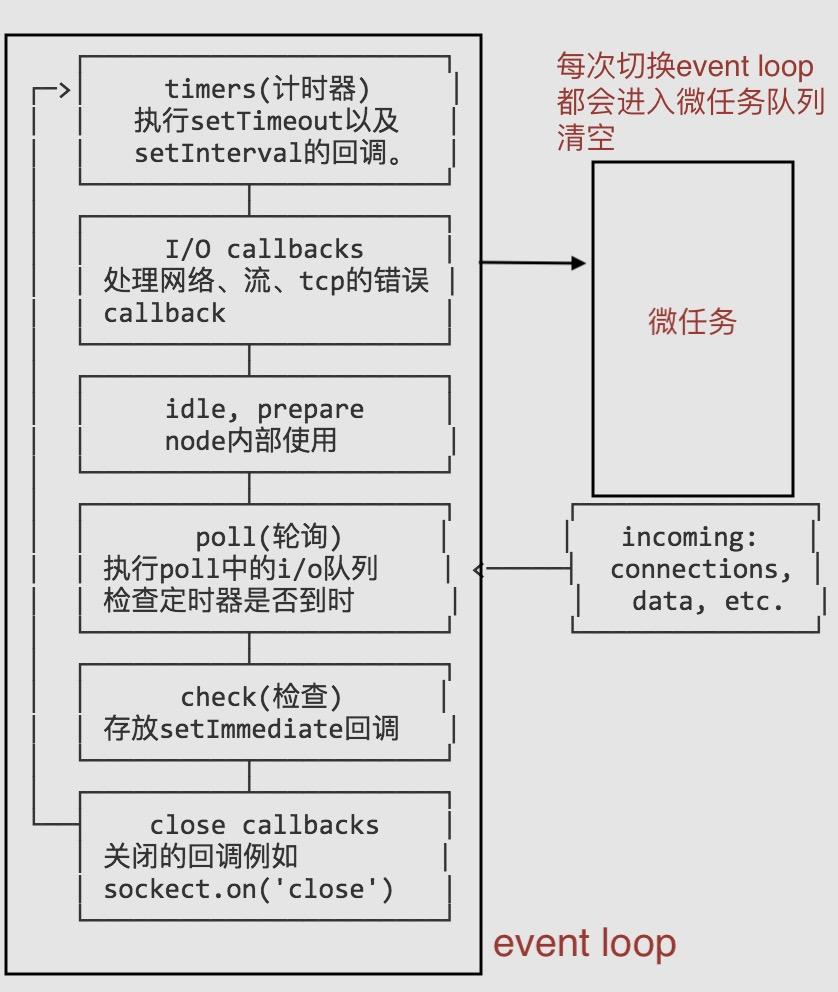
timers: 执行setTimeout和setInterval中到期的callback。pending callback: 上一轮循环中少数的callback会放在这一阶段执行。idle, prepare: 仅在内部使用。poll: 最重要的阶段,执行pending callback,在适当的情况下回阻塞在这个阶段。check: 执行setImmediate(setImmediate()是将事件插入到事件队列尾部,主线程和事件队列的函数执行完成之后立即执行setImmediate指定的回调函数)的callback。close callbacks: 执行close事件的callback,例如socket.on('close'[,fn])或者http.server.on('close, fn)。
timers
计时器指定可执行所提供回调的阈值,而不是用户希望其执行的确切时间。计时器回调将尽可能早地运行,因为它们可以在指定的时间间隔后进行调度。但是,操作系统调度或其它回调的运行可能会延迟它们。
pending callbacks
此阶段执行某些系统操作(例如 TCP 错误类型)的回调。 例如,如果TCP socket ECONNREFUSED在尝试 connect 时 receives,则某些* nix 系统希望等待报告错误。 这将在pending callbacks阶段执行。
poll
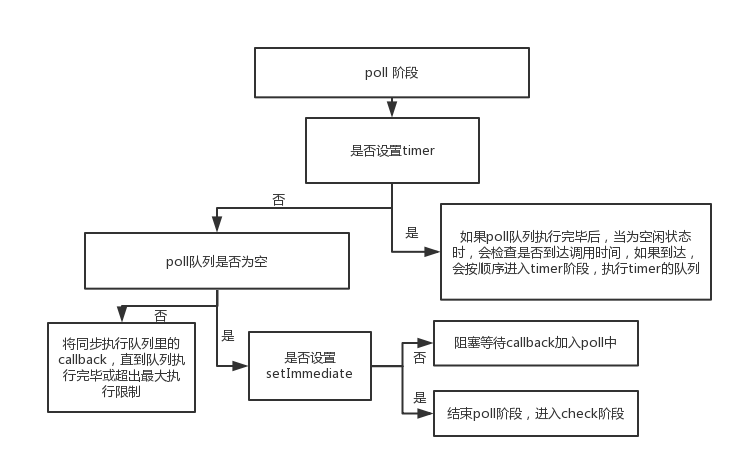
poll 是一个至关重要的阶段,
当进入到 poll 阶段,并且没有 timers 被调用的时候,会发生下面的情况:
(1)如果 poll 队列不为空:
- Event Loop 将同步的执行 poll queue 里的 callback(新的 I/O 事件),直到 queue 为空或者执行的 callback 到达上线。
(2)如果 poll 队列为空:
- 如果脚本调用了 setImmediate(), Event Loop 将会结束 poll 阶段并且进入到 check 阶段执行 setImmediate()的回调。
- 如果脚本没有 setImmediate()调用,Event Loop 将会等待回调(新的 I/O 事件)被添加到队列中,然后立即执行它们。
当进入到 poll 阶段,并且调用了 timers 的话,会发生下面的情况:
- 一旦 poll queue 是空的话,Event Loop 会检查是否 timers, 如果有 1 个或多个 timers 时间已经到达,Event Loop 将会回到 timer 阶段并执行那些 timer 的 callback(即进入到下一次 tick)
伪代码
enter pool phase:
if (has timer scheduled) {
// 官方没有提到这种情况会做什么
}
else {
if (isEmpty(queue)) {
if (has(setImmediate)) {
// 进入check阶段
}
else if (!isEmpty(timer)) {
// 回到timer阶段
}
else {
}
// 目前看来只有存在setImmediate时才会进入check阶段,这肯定不合理
}
if (!isEmpty(queue)) {
let result = execute(queue);
if (result === 'queue is empty') {
// 官方没讲后续逻辑
// 猜测是回到队列为空的处理逻辑中
}
if (result === 'reached hard limit') {
// 官方没有解释这里的后续逻辑
// 也许与queue is empty一样对待
}
}
}
check 阶段
setImmediate()实际上是一个特殊的 timer,跑在 event loop 中一个独立的阶段。它使用 libuv 的 API
来设定在 poll 阶段结束后立即执行回调。
通常上来讲,随着代码执行,event loop 终将进入 poll 阶段,在这个阶段等待 incoming connection, request 等等。但是,只要有被 setImmediate()设定了回调,一旦 poll 阶段空闲,那么程序将结束 poll 阶段并进入 check 阶段,而不是继续等待 poll 事件们 (poll events)。
close callbacks 阶段
如果一个 socket 或 handle 被突然关掉(比如 socket.destroy()),close 事件将在这个阶段被触发,否则将通过 process.nextTick()触发
Node eventLoop 具体执行流程
进入 node 的 eventLoop 之前
整个 JS 作为宏任务会跑一遍,如果产生了新的微任务会一起跑完 注意:
- 微任务只会有两种,且 process.nextTick 优先于 Promise.then 执行
- 这里跑 JS 的时候只会跑完微任务,因为所有的宏任务都会对应有 Node 事件循环里的某个阶段来专门执行
进入 eventLoop 后
- 分别执行每个阶段注册的回调
- 每个阶段执行完一个宏任务的时候都会清空微任务队列(老版本是宏任务一个一个执行完直到阶段结束才清空微任务队列)
图解 eventLoop
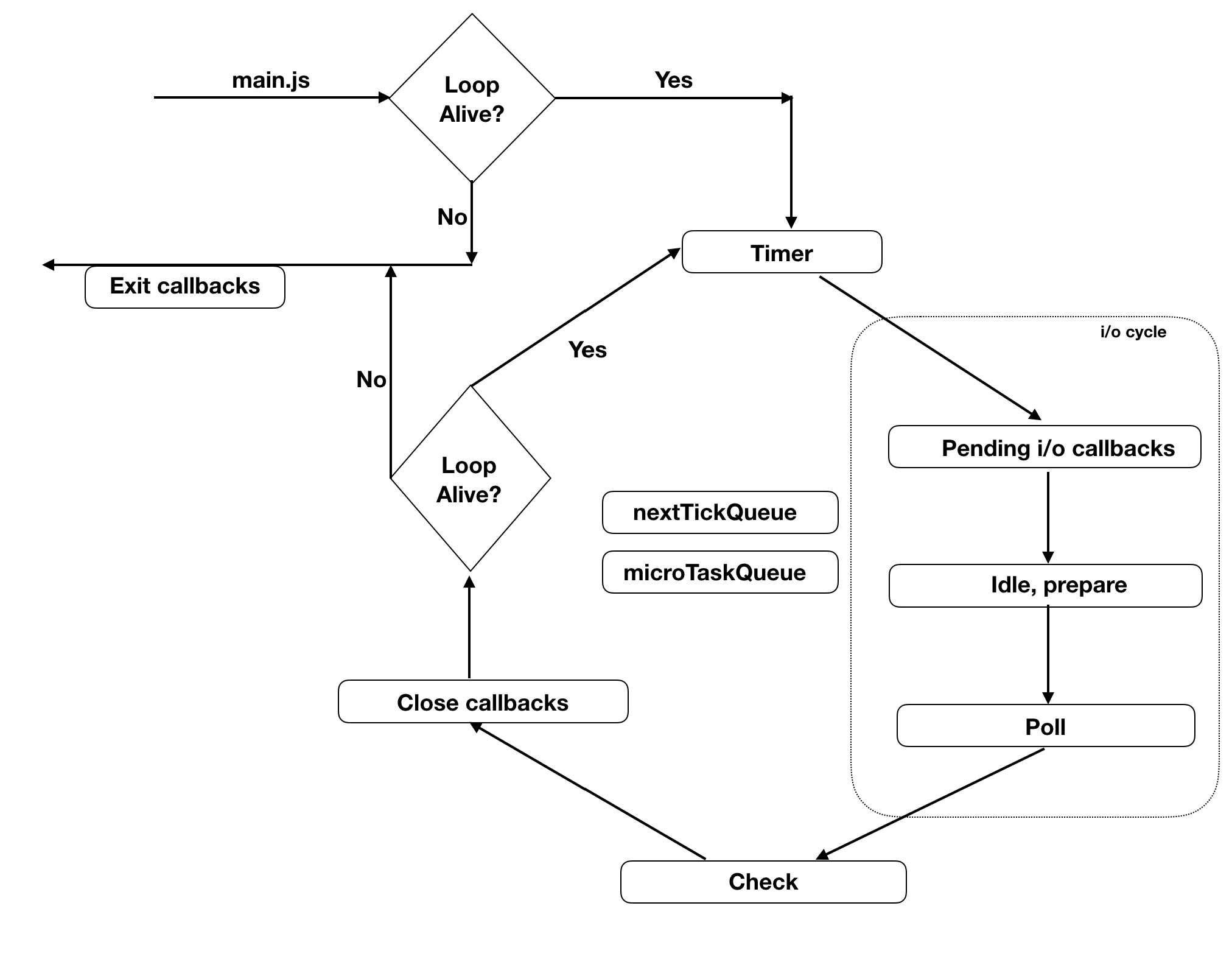
事件循环原理总结
- node 的初始化
- 初始化 node 环境。
- 执行输入代码。
- 执行 process.nextTick 回调。
- 执行 microtasks。
- 进入 event-loop
- 进入 timers 阶段
- 检查 timer 队列是否有到期的 timer 回调,如果有,将到期的 timer 回调按照 timerId 升序执行。
- 检查是否有 process.nextTick 任务,如果有,全部执行。
- 检查是否有 microtask,如果有,全部执行。
- 退出该阶段。
- 进入IO callbacks阶段。
- 检查是否有 pending 的 I/O 回调。如果有,执行回调。如果没有,退出该阶段。
- 检查是否有 process.nextTick 任务,如果有,全部执行。
- 检查是否有 microtask,如果有,全部执行。
- 退出该阶段。
- 进入 idle,prepare 阶段:
- 这两个阶段与我们编程关系不大,暂且按下不表。
- 进入 poll 阶段
- 首先检查是否存在尚未完成的回调,如果存在,那么分两种情况。
- 第一种情况:
- 如果有可用回调(可用回调包含到期的定时器还有一些 IO 事件等),执行所有可用回调。
- 检查是否有 process.nextTick 回调,如果有,全部执行。
- 检查是否有 microtaks,如果有,全部执行。
- 退出该阶段。
- 第二种情况:
- 如果没有可用回调。
- 检查是否有 immediate 回调,如果有,退出 poll 阶段。如果没有,阻塞在此阶段,等待新的事件通知。
- 第一种情况:
- 如果不存在尚未完成的回调,退出 poll 阶段。
- 首先检查是否存在尚未完成的回调,如果存在,那么分两种情况。
- 进入 check 阶段。
- 如果有 immediate 回调,则执行所有 immediate 回调。
- 检查是否有 process.nextTick 回调,如果有,全部执行。
- 检查是否有 microtaks,如果有,全部执行。
- 退出 check 阶段
- 进入 closing 阶段。
- 如果有 immediate 回调,则执行所有 immediate 回调。
- 检查是否有 process.nextTick 回调,如果有,全部执行。
- 检查是否有 microtaks,如果有,全部执行。
- 退出 closing 阶段
- 检查是否有活跃的 handles(定时器、IO 等事件句柄)。
- 如果有,继续下一轮循环。
- 如果没有,结束事件循环,退出程序。
- 进入 timers 阶段
事件循环的每一个子阶段退出之前都会按顺序执行如下过程:
- 检查是否有 process.nextTick 回调,如果有,全部执行。
- 检查是否有 microtaks,如果有,全部执行。
- 退出当前阶段。
eventloop 伪代码
while (true) {
loop.forEach((阶段) => {
阶段全部任务()
nextTick全部任务()
microTask全部任务()
})
loop = loop.next
}
问题来了 nextTick 有什么作用
Node.js 适合 I/O 密集型的应用,而不是计算密集型的应用, 因为一个 Node.js 进程只有一个线程,因此在任何时刻都只有一个事件在执行。如果这个事 件占用大量的 CPU 时间,执行事件循环中的下一个事件就需要等待很久,因此 Node.js 的一个编程原则就是尽量缩短每个事件的执行时间。
process.nextTick() 提供了一个这样的工具,可以把复杂的工作拆散,变成一个个较小的事件。 使其不阻塞当前的tick。
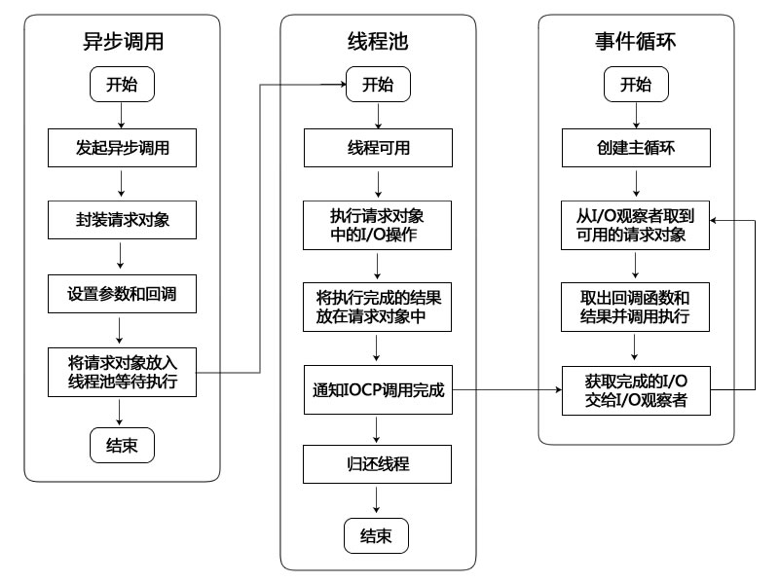
node 如何实现异步 IO
nodejs 会先从 js 代码通过 node-bindings 调用到 C/C++代码,然后通过 C/C++代码封装一个叫 “请求对象” 的东西交给 libuv,这个请求对象里面无非就是需要执行的功能+回调之类的东西,给 libuv 执行以及执行完实现回调。
总结来说,一个异步 I/O 的大致流程如下:
1、发起 I/O 调用
用户通过 Javascript 代码调用 Node 核心模块,将参数和回调函数传入到核心模块;
Node 核心模块会将传入的参数和回调函数封装成一个请求对象;
将这个请求对象推入到 I/O 线程池等待执行;
Javascript 发起的异步调用结束,Javascript 线程继续执行后续操作。
2、执行回调
I/O 操作完成后,会取出之前封装在请求对象中的回调函数,执行这个回调函数,以完成 Javascript 回调的目的。
node 并发的处理
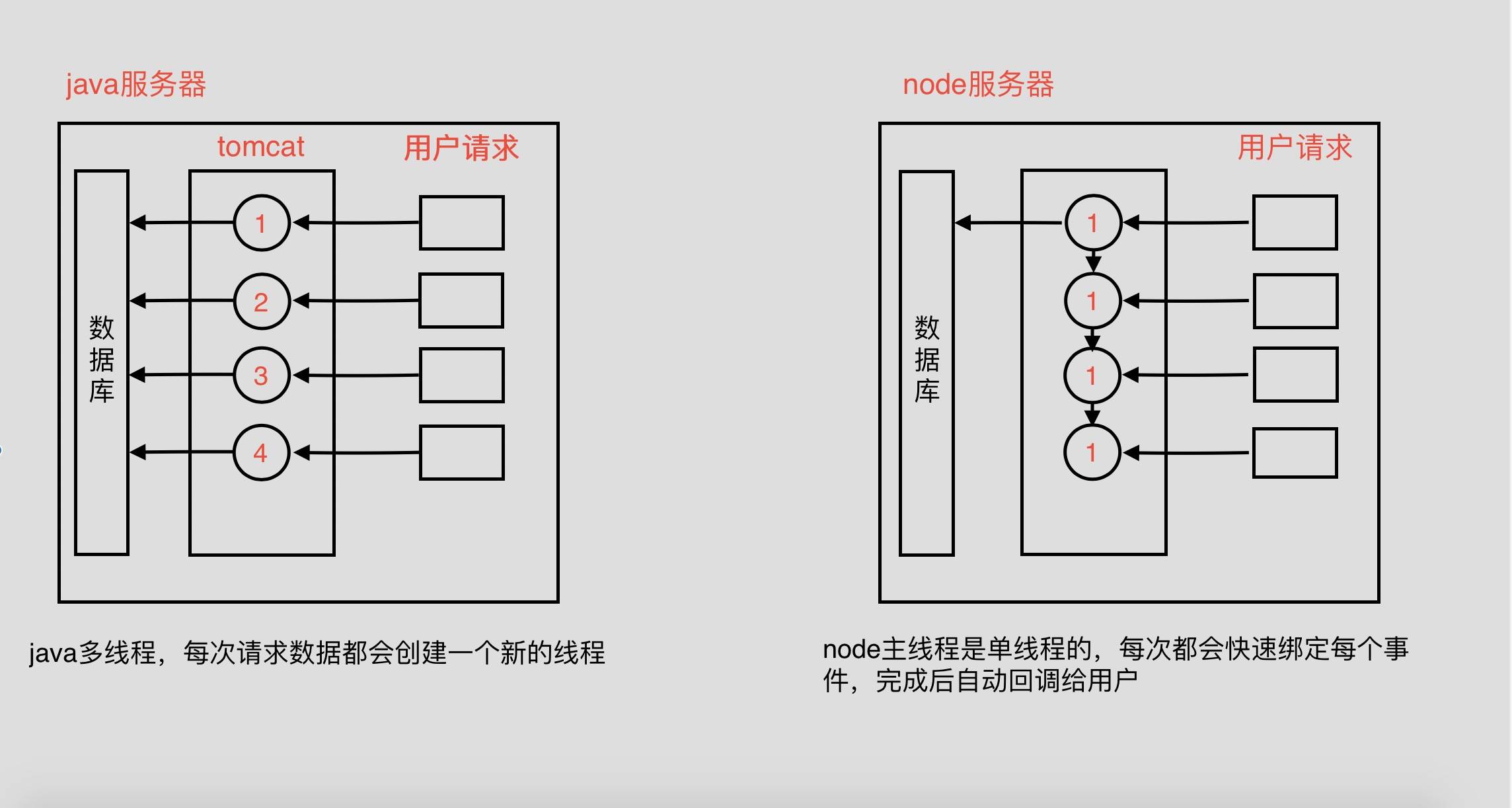
- 当用户请求量增高时,node 相对于 java 有更好的处理
并发性能,它可以快速通过主线程绑定事件。java 每次都要创建一个线程,虽然 java 现在有个线程池的概念,可以控制线程的复用和数量。 - 异步 i/o 操作,node 可以更快的操作数据库。java 访问数据库会遇到一个并行的问题,需要添加一个锁的概念。我们这里可以打个比方,下课去饮水机接水喝,java 是一下子有喝多人去接水喝,需要等待,node 是每次都只去一个人接水喝。
- 密集型 CPU 运算指的是逻辑处理运算、压缩、解压、加密、解密,node 遇到 CPU 密集型运算时会阻塞主线程
(单线程),导致其下面的时间无法快速绑定,所以node不适用于大型密集型CPU运算案例,而 java 却很适合。
单线程的Node的优劣势
单线程:
- 无需像多线程那样去关注线程之间的状态同步问题
- 没有线程切换所带来的开销
- 没有死锁存在
当然单线程也有许多坏处:
- 无法充分利用多核CPU
- 大量计算占用CPU会导致应用阻塞(即不适用CPU密集型)
- 错误会引起整个应用的退出